Ich denke so langsam habe ich für mich selbst herausgefunden, was „2.0“ in der durch das Internet angestossenen weltweiten Diskussion eigentlich ist. Das Kürzel „2.0“ ist für mich eine neue Perspektive die Dinge zu sehen. Es ist keine Technologie, es ist kein Wundermittel, es ist kein Marketingbuzz und es ist ganz sicher kein Schwachsinn oder Hype. Denn wie sollte etwas Unsinn sein, das einem eine neue Perspektive verschafft?
Bild anklicken für große Abbildung (Download als PDF)
Web 2.0 ist dabei nur ein kleiner Teil. Denn eigentlich bedeutet Web 2.0 folgendes:
Web = ich betrachte das WWW und seine Entwicklung
2.0 = Ich betrachte irgendetwas unter der neuen Perspektive des „bringing people together“ via the internet und was das für Folgen haben wird
Web + 2.0 = Ich betrachte das WWW unter der Perspektive des „bringing people together“-Effekt und was es für Folgen haben wird
2.0 ist ganz klar eine Perspektive, ich schaue mir bestehende sozio-kulturelle Institutionen und Errungenschaften wie z.B. School, University, Enterprise, Family an und betrachte sie wie als wäre ich neu in diese Welt geboren. Und dann beginne ich Fragen zu stellen:
- Was könnte sich in der „Schule“ eigentlich verändern: School 2.0
- Was könnte sich in der „Universität“ eigentlich verändern: University 2.0
- Was könnte sich in dem „Unternehmen“ eigentlich verändern: Enterprise 2.0
- Was könnte sich in der „Familie“ eigentlich verändern: Family 2.0 (via Martin Ebner)
Was hier also stattfindet ist ein gesellschaftlicher Entwicklungssprung und nicht primär ein technischer. Es geht um einen kulturellen Sprung in die Zukunft, und Technologie sowie digitale Medien sind nur das Hilfsmittel dafür. Ein Beispiel, „Family 2.0“ bedeutet für mich, dass ich meinen Eltern Fotos per flickr-Album zusende, mit Ihnen am Wochenende eine Videokonfrenz machen kann, auch wenn sie weit weg wohnen und meine Weihnachtswünsche per E-Mail mit Link versehen austauschen kann. Und es bedeutet, wenn ein Familienmitglied keinen Internetzugang+Rechner hat, das dieses an dieser neuen Familienkultur NICHT teilnehmen kann.
Ähnliche Veränderungen und neue Aspekte lassen sich in nahezu jedem Bereich unserer Gesellschaft finden. „2.0“ ist aus meiner Sicht die kulturelle Perspektive einer sich weltweit verändernden Gesellschaft. Davon sind Bildungs-, Arbeits- und Freizeitstrukturen gleichermaßen erfasst.
Das allerwichtigste jedoch an „2.0“ ist aus meiner Sicht: 2.0 ist schon 100% da, nur noch leider sehr, sehr unregelmäßig verteilt. Deshalb lohnt es sich denke ich mitzuarbeiten an einer besseren Verteilung. 2.0 wird dort auf Ablehnung treffen, wo notorische Betonköpfe das Ruder in der Hand halten. Dort wo Perspektivenwechsel unmöglich ist, wo Personen einen Gesichtskreis vom Radius Null haben und diesen dann ihren Standpunkt nennen (Hilbert).
Update 9.12.2007
In diesem Zusammenhang ist es auch mal ganz erhellend, was ich zu 2.0 bislang so geschrieben habe. Man entwickelt sich doch weiter irgendwie…
Update 12.12.2007
Ein Whitepaper zu dem Bereich „2.0“ (als PDF) ist vor kurzem erschienen von Lee Hopkins, Titel „An introduction to the power of Web2.0-Social Media – How I learned to stop worrying and love communication“. Darin werden auch die besonderen Aspekte von Tools vorgestellt. Schön fand ich „Twitter“ als „Thought-sharing“-Tool zu sehen. (via Nerd30)
Update 7.7.2009
 Anlässlich des Web 2.0 Summit in San Francisco im Oktober 2009, haben Tim O’Reilly und John Battelle einen interessanten Beitrag geschrieben, in dem er sich mit dem von ihm selbst geschaffenen Begriff des Web 2.0 auseinandersetzt. Der Beitrag mit dem Titel „Web Squared: Web 2.0 Five Years On“ enthält einige interessante Zwischenstatements, z.B.:
Anlässlich des Web 2.0 Summit in San Francisco im Oktober 2009, haben Tim O’Reilly und John Battelle einen interessanten Beitrag geschrieben, in dem er sich mit dem von ihm selbst geschaffenen Begriff des Web 2.0 auseinandersetzt. Der Beitrag mit dem Titel „Web Squared: Web 2.0 Five Years On“ enthält einige interessante Zwischenstatements, z.B.:
- Web 2.0 is all about harnessing collective intelligence.
- A key competency of the Web 2.0 era is discovering implied metadata, and then building a database to capture that metadata and/or foster an ecosystem around it.
- Data analysis, visualization, and other techniques for seeing patterns in data are going to be an increasingly valuable skillset. Employers take notice. […] Mapping from unstructured data to structured data sets will be a key Web Squared competency.
- As a result, there’s a new information layer being built around Twitter that could grow up to rival the services that have become so central to the Web: search, analytics, and social networks. Twitter also provides an object lesson to mobile providers about what can happen when you provide APIs. Lessons from the Twitter application ecosystem could show opportunities for SMS and other mobile services, or it could grow up to replace them.
- Businesses must learn to harness real-time data as key signals that inform a far more efficient feedback loop for product development, customer service, and resource allocation.
Zu dem ganzen Komplex ist ein Whitepaper (als PDF) downloadbar.
Why do I blog this? Ich denke, man darf 2.0 nicht mit Hype verwechseln. Einen kulturellen Wandel als Hype fehlzuinterpretieren hieße die Entwicklung zu verpassen und Chancen ungenutzt verstreichen zu lassen. Mich würde interessieren, wie das andere sehen. Ist es eine Kulturrevolution mit neuer Perspektive auf die Dinge, oder ein schnöder Hype?
Mir selbst ist klar, dass Lem Recht hatte (denn das ist meine Erfahrung in der Uni): „Viele, die Ihrer Zeit vorausgeeilt waren, mußten auf sie in sehr unbequemen Unterkünften warten.“ (Stanislaw Lem)

 This book is clearly a candidate for the subject „Missing manuals on …“. Several days ago Karsten passed me a book having this title „Presenting Your Findings – A Practical Guide for Creating Tables“ (see table of contents for more). This is not about building Excel-Sheets or something alike. It is about how to present statistical data found during research. And yeah, this book might have helped a lot before I started creating my tables in LaTeX.
This book is clearly a candidate for the subject „Missing manuals on …“. Several days ago Karsten passed me a book having this title „Presenting Your Findings – A Practical Guide for Creating Tables“ (see table of contents for more). This is not about building Excel-Sheets or something alike. It is about how to present statistical data found during research. And yeah, this book might have helped a lot before I started creating my tables in LaTeX.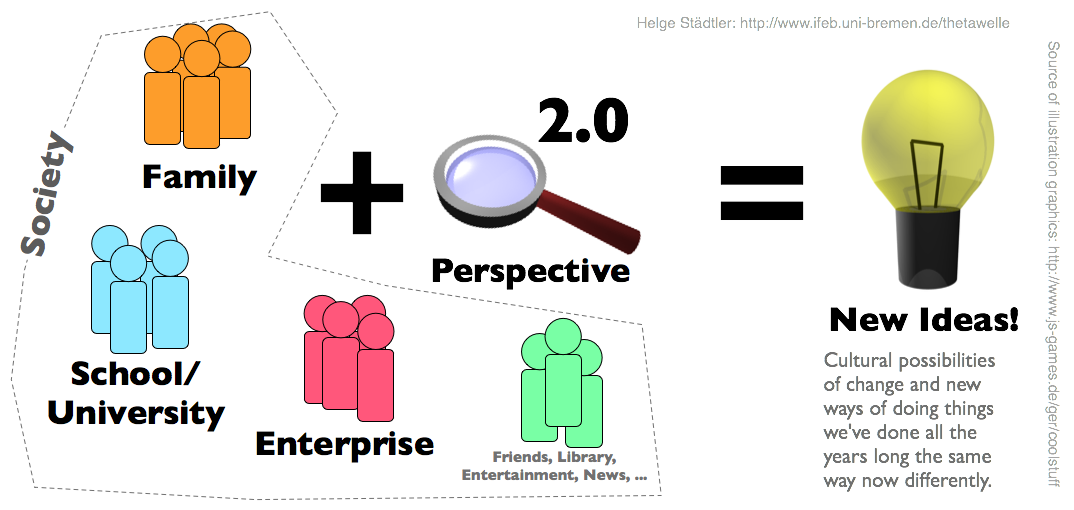
 Die
Die 
