Der eine oder andere hat vielleicht schonmal von Fefe’s Blog gehört. Das ist eine Blog-Installation, die durch die Person Felix von Leitner mit regelmäßigen Inhalten gefüllt wird. Ich weiß nicht wann ich zum ersten Mal mit dem Blog in Berührung gekommen bin, aber das muss so um den 27c3 herum gewesen sein. Ich bin zum ersten Mal mit Inhalten von Fefe konfrontiert worden im Rahmen der Fnord News Show bzw. der Fnord Jahresrückblick 2009 auf dem Chaos Communication Congress 26c3 (mein erster Congress).
Als ich zum Zeitpunkt des 27c3 ein Jahr später Langeweile hatte, begann ich während wir mit einigen CCC’lern dem 27c3 per Videostream beiwohnten, eine kleine iOS App zu basteln, die Inhalte von Fefe’s Blog per RSS-Feed abholen und anzeigen sollte. Die erste primitive Version funktionierte bereits gegen Ende des 27c3 auf meinem Development iDevice, damals noch ein iPhone 3GS.
Nachdem die App einigermaßen stabil lief, packte ich die einfach kostenlos in den AppStore. Zu dem Zeitpunkt war ich ein eher schlechter iOS Developer (weil noch Anfänger in Sachen iOS) und ich habe iOS an einigen Stellen absolut nicht verstanden. Die App lief zwar, aber sie hatte einige extrem CPU-ineffiziente Stellen, da ich ein paar fancy Animationen haben wollte und die Renderingmechanismen bis zur Unkenntlichkeit falsch benutzt habe.
Die Fefe App (2010)
Hier ein Rückblick auf die erste Version der App die so um 2012 existierte und durchaus eine recht lustige User Experience bot durch die fancy Animationen:
| Launch Screen |
Postingübersicht |
Posting mit Kommentaren |
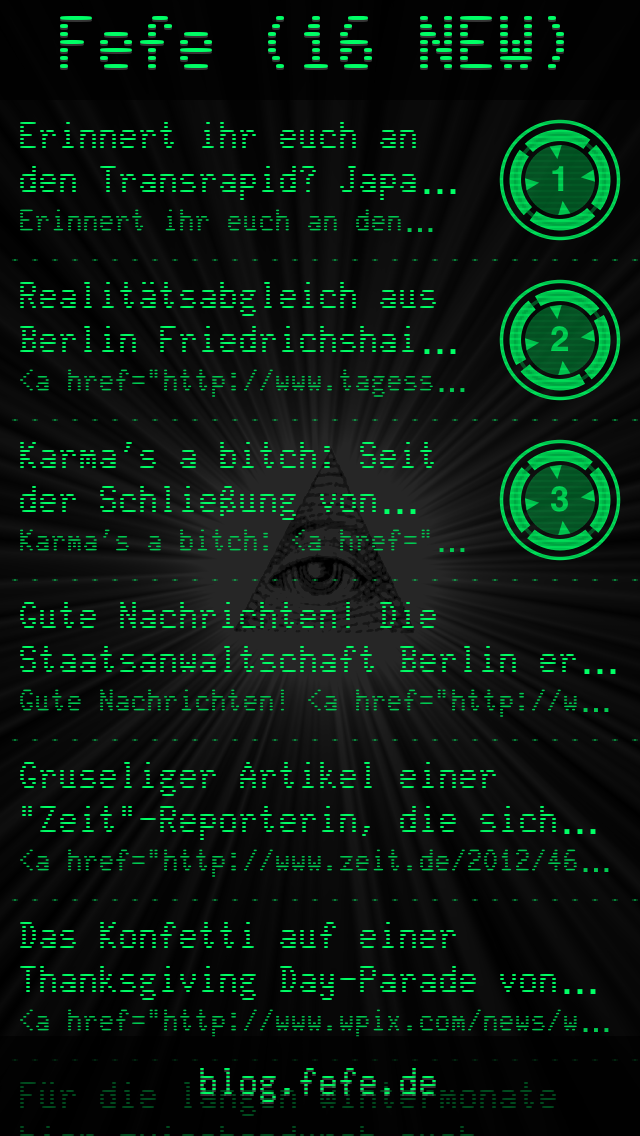
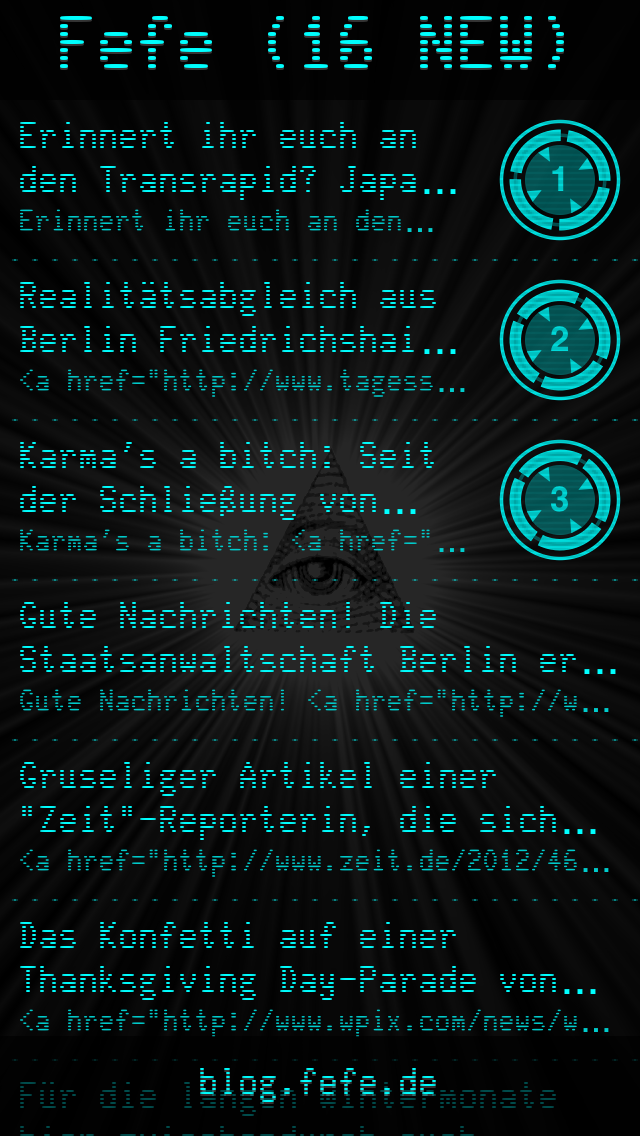
Farbschema grün |
Farbschema Cyan |
 |
 |
 |
 |
 |
All diese runden Gebilde drehte sich in sich selbst und es gab ein herrlich dynamisches Gesamtbild. Man beachte, dass es zu dieser Zeit Kommentare zu Fefe’s Blog gab über eine nicht zum Blog selbst gehörende URL als Service refefe (http://blog.refefe.de/rss.xml). Das heisst Leute konnten da extern kommentieren und als ich das mitbekommen hatte, hab ich die Kommentare natürlich ebenfalls in der App angezeigt.
Aufgebaut hatte den re:Fefe-Service (vermutlich auch aus blossem Spass an der Freud) Linus Neumann. In 2013 hielt Linus zusammen mit anderen dazu einen recht empfehlenswerten und kurzweiligen Vortrag mit dem Titel „Die Trolldrossel (Erkenntnisse der empirischen Trollforschung)“ (hier bei Youtube).
Später bekam Linus für diese Aktion noch eine Abmahnung von Fefe’s Anwalt (zumindest sah das für Außenstehende so aus) das Schreiben (Seite 1, Seite 2, Seite 3) schaut zunächst ernstgemeint aus, aber das Veröffentlichungsdatum 1. April sollte bereits stutzig machen.
Und so berechtigt war es dann auch die Echtheit zu bezweifeln. Die Aufklärung zu dem Schreiben wurde auf der Anwaltsseite selbst veröffentlicht mit dem Wortlaut:
[…] Nachdem die Trollkommentar-Datenbank bemerkenswerte Ausmaße annahm und damit repräsentative Auswertung erlaubte, war es an der Zeit, das re Fefe-Blog würdig zu beenden.
Ein bloßes Abschalten hätten jedoch die Trolle nicht verstanden und als Zensur bewertet. Zudem konnte niemand voraussagen, wie die Trolle auf einen kalten Entzug reagieren würden. Um sich aus der Schusslinie zu nehmen, bat mich Linus um einen anwaltlichen False Flag-Angriff in Form einer 1.April-Abmahnung, die gegenüber den Trollen das Abschalten „erklärte“. Fefe war natürlich eingeweiht und einverstanden. […]
Der ReFefe-Service und die Kommentare wurden dann im April 2014 eingestellt mit Hinweis auf das Fake-Anwaltsschreiben mit dem folgenden Hinweis:
Da mir rechtliche Konsequenzen drohen, muss ich diese Seite leider schließen.
Mein Anwalt rät mir, mich nicht zum laufenden Verfahren zu äußern.
Ich hoffe ihr habt dafür Verständnis.
Mich hat damals – als ich begann Fefe’s Inhalte zu besuchen – denke ich die reine Sensationslust zu diesem Blog getrieben. Ich fand die Art und Weise wie dort polarisiert wurde vermutlich anziehend. Heute würde ich sagen, es war viel mehr mein Ego das von diesem Blog angezogen wurde. Das Ego, das nach einfachen Lösungen nach klaren Bewertungen, nach Empörung gesucht hat, um sich sein eigenes vielfach negatives Weltbild zu verstärken. Ich war unwissend. Mein Blick war verstellt. Mein Unbewusstsein hat es geschehen lassen, dass ich für dieses Blog eine App erstellt habe, die möglicherweise sogar noch zu dessen Popularität beigetragen hat (ebenso wie übrigens Re:Fefe).
Primär hatte mich eigentlich nur interessiert, iOS Aps zu entwickeln und die Möglichkeiten des iDevice auszureizen. Ich wollte mich optisch mit dem Userinterface alternativ ausprobieren und zugleich ein wenig mit CoreGraphics und CoreAnimation – zwei wichtigen iOS Frameworks – Spass haben. Rückblickend bedauere ich es sehr, für dieses Blog eine App entwickelt zu haben.
Nunja die Zeit ging ins Land, da die App funktionierte, bekam sie lange Zeit kein Update. iOS 7 brachte dann den großen UI-Style-Wechsel in UIKit und es war notwendig alle Apps anzupassen. Da ich eine Menge eigener Apps anpassen musste, nahm ich das zum Anlass eine zweite Version der App zu entwickeln und die Fefe App damit ebenso an den neuen Stil anzupassen. Diesmal, um meine Learnings im iOS Development einzubringen und das UI deutlich effizienter und performanter zu bauen. Für mich war es wieder eher die technische Challenge die mich erneut dazu trieb die App zu erweitern.
Die 0xfefe App (2014)
Es entstand die 0xfefe App, die App im Store wurde also auch umbenannt von Fefe in 0xfefe. Ziel der neuen Version war zugleich, die App nicht mehr ausschließlich an Fefe’s Blog zu koppeln. Stattdessen sollte die App beliebige RSS-Feeds als Quelle nutzen können. Diese App war daher in der Lage, jede beliebige RSS-Feed-URL als Konfiguration zu verwenden und den Feed dahinter anzuzeigen. Das ließ sich über die iOS Settings konfigurieren und war auch meine technische Rückversicherung, falls Apple die App wegen der Inhalte ablehnen sollte. Wär die App abgelehnt worden, hätte ich einfach einen anderen RSS-Feed integriert und den Nutzern einen Hinweis eingeblendet, wie sie ihr Lieblingsblog selbst konfigurieren könnten.
In der Praxis, haben allerdings lange nicht alle RSS-Feeds so gut mit der App funktioniert, wie der Feed von Fefe’s Blog, was daran lag, dass viele der RSS-Feeds da draussen im Web keine Full-Content-Feeds sind. Ich selbst hab nur während der Entwicklung andere Feeds konfiguriert, um zu testen, ob alles damit klar geht. Im täglichen Betrieb hatte ich nie eine andere URL konfiguriert.
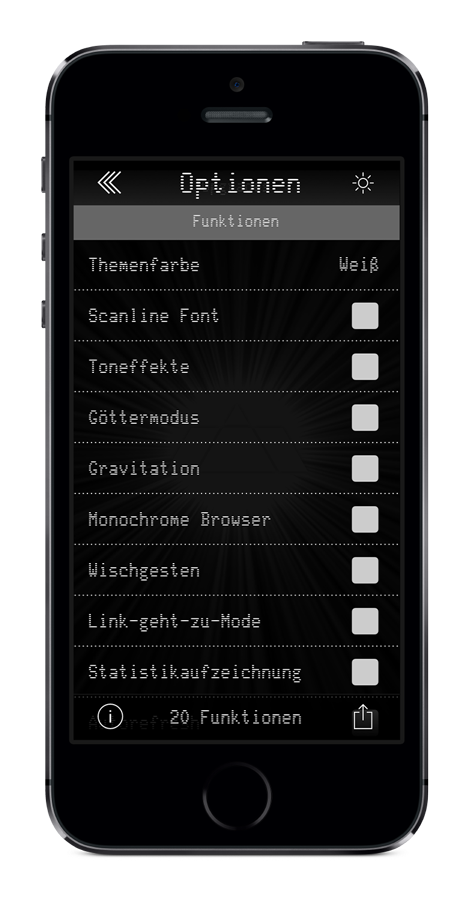
Die zweite Version der App war letztlich ein weitreichender Rewrite. Das gesamte UI wurde neu geschrieben und auch um eine SoundEngine mit vielen lustigen Sounds bereichert. Es gab Favoriten und Statistiken und umfangreiche Konfigurationsoptionen. Viele neue Farbschemata kamen hinzu (inklusive eines Tageslicht-Scheme; das früh die Dark-/Light-Theme Features die heute normal sind vorwegnahm), und die fancy Animationen der Post-Entry-Buttons wurden auf CoreAnimation-konforme Technik umgestellt, die nur einen winzigen Bruchteil der vorherigen Performance schluckte.
Wem einige der App Sounds bekannt vorkamen, der hat vielleicht bemerkt, dass ich einige Sounds aus einer Flash-Datei extrahiert hatte, die damals von Kim Schmitz (alias Kimble) auf seiner Webseite kimvestor abrufbar war. Ich fand die Sounds so schön futuristisch und da es mir ja lediglich um ein Spassprojekt ging, hab ich da auch beherzt reverse-engineered, um die Sounds aus der kimvestor-flash-Datei zu extrahieren.
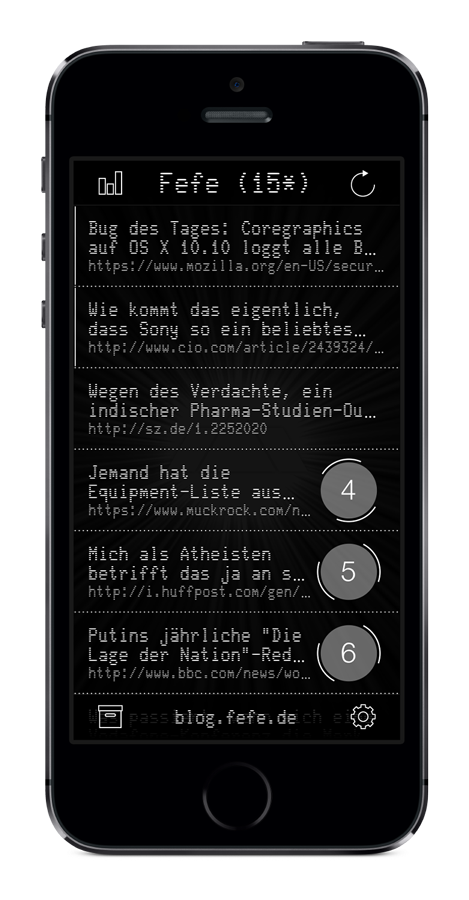
Hier ein Überblick über die App Version 2:
| Postingübersicht |
Posting |
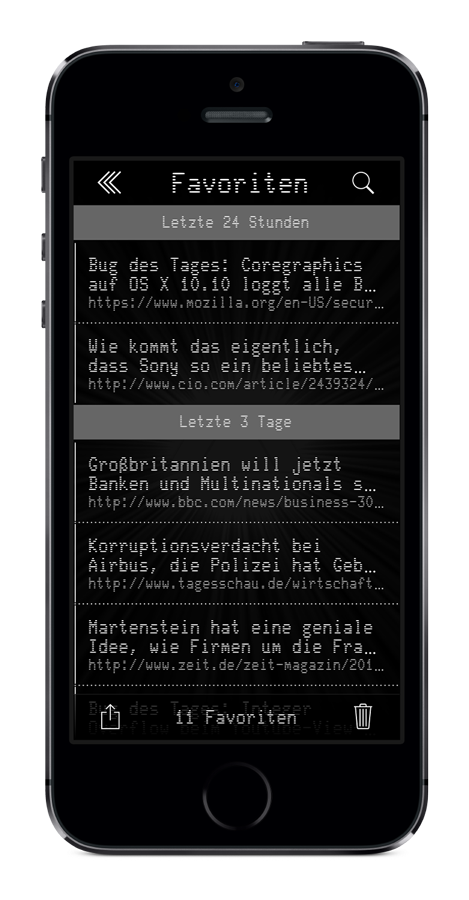
Favoriten |
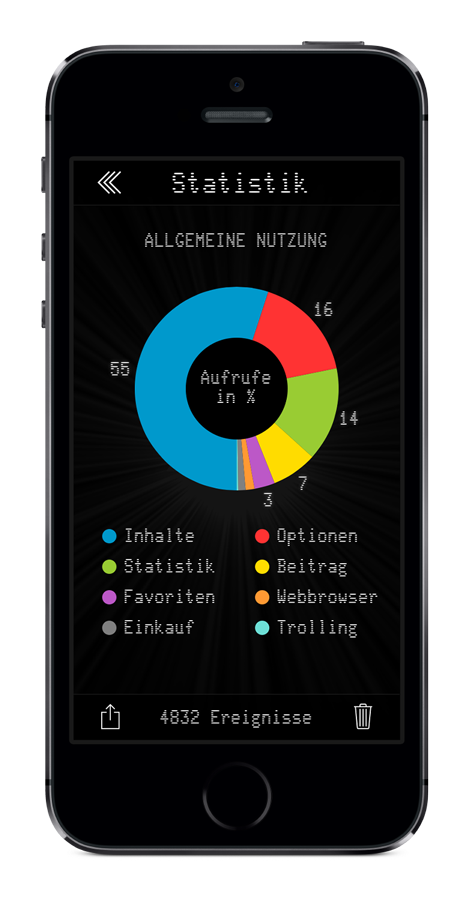
Statistik |
Einstellungen |
 |
 |
 |
 |
 |
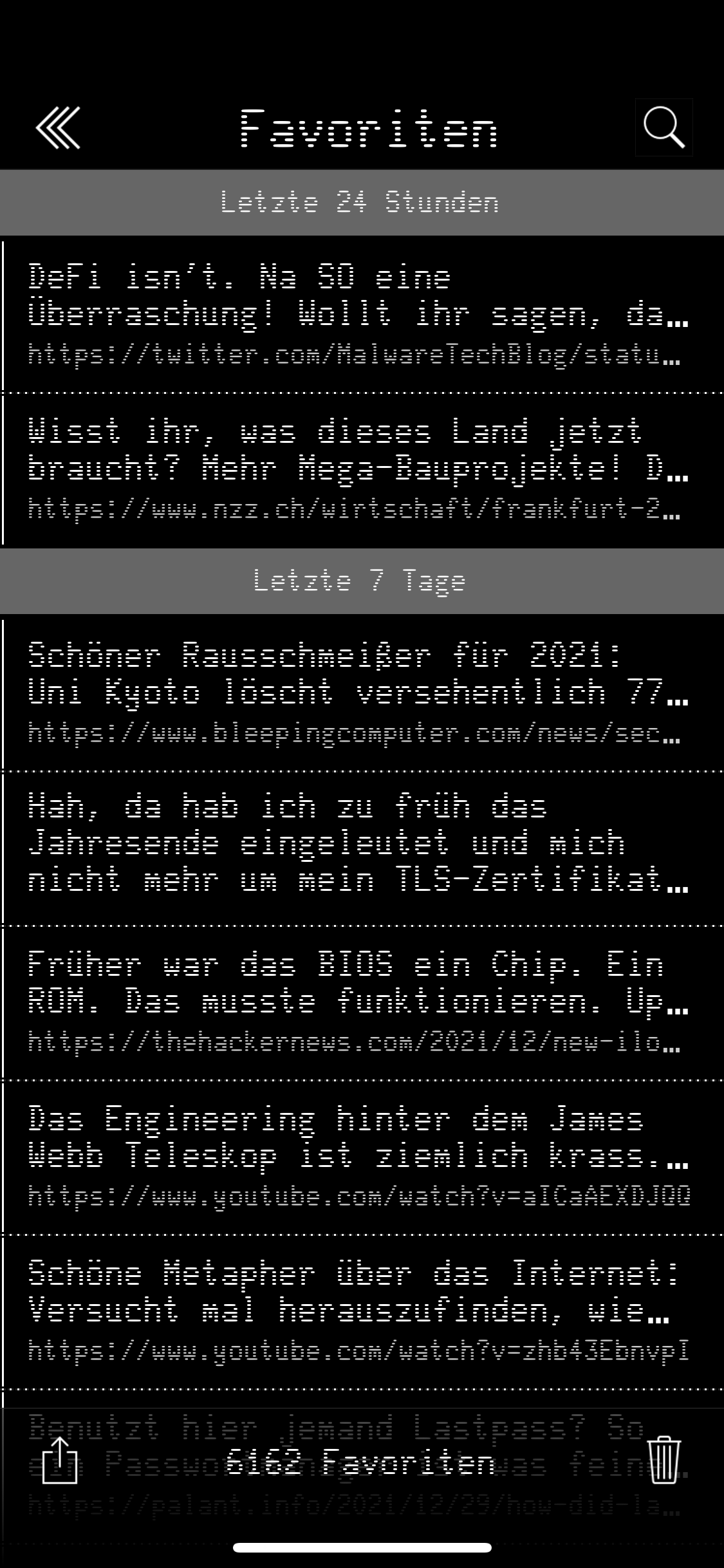
Wie man in den Screenshots sehen kann, kamen eine Menge nützlicher Features hinzu. Unter anderem gab es jetzt einen Favoriten-Speicher. Jeder favorisierte Post wurde auf dem iPhone in der App persistent gespeichert und war Volltext-durchsuchbar und -exportierbar. Das war durchaus nützlich, wenn man mal einen Post von Fefe auf die Schnelle gesucht hat.
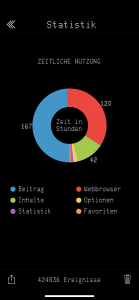
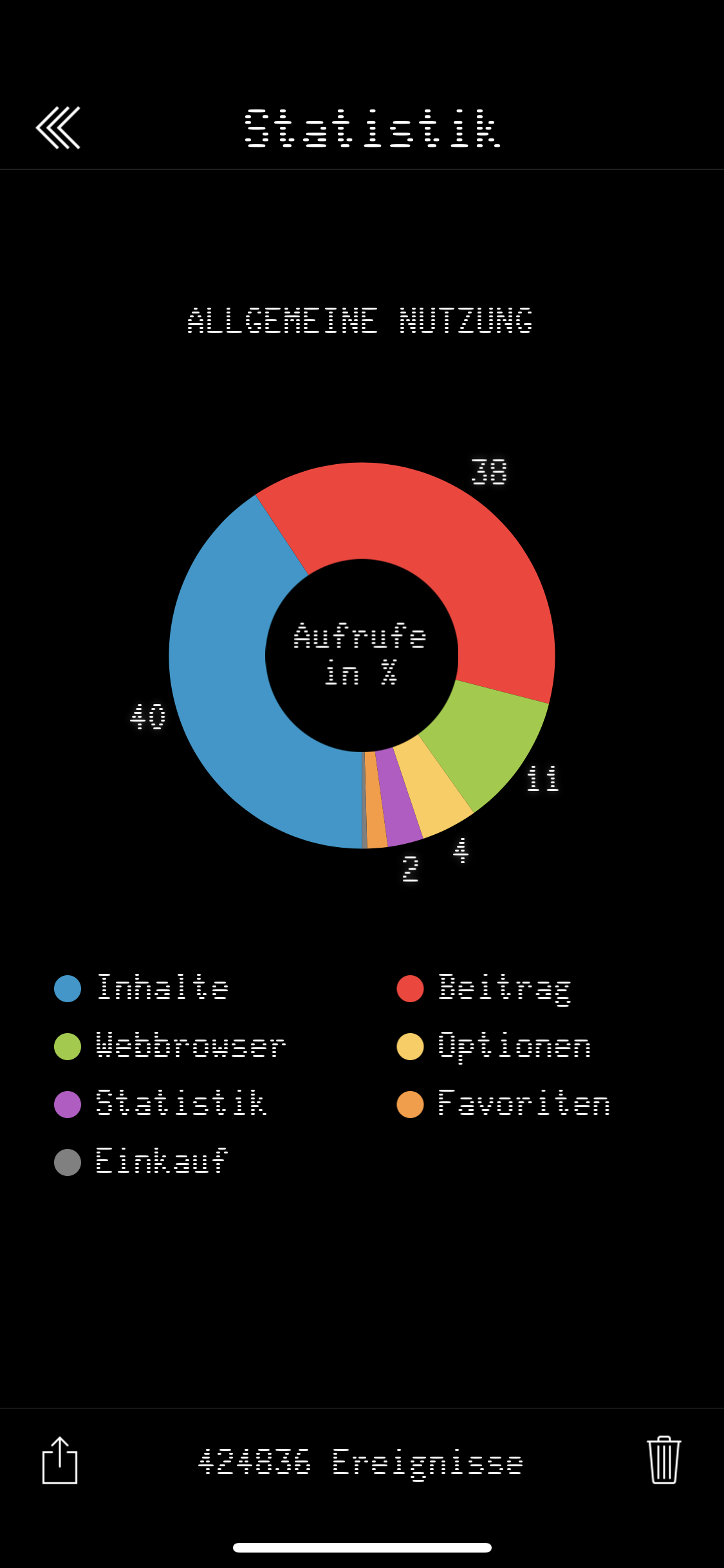
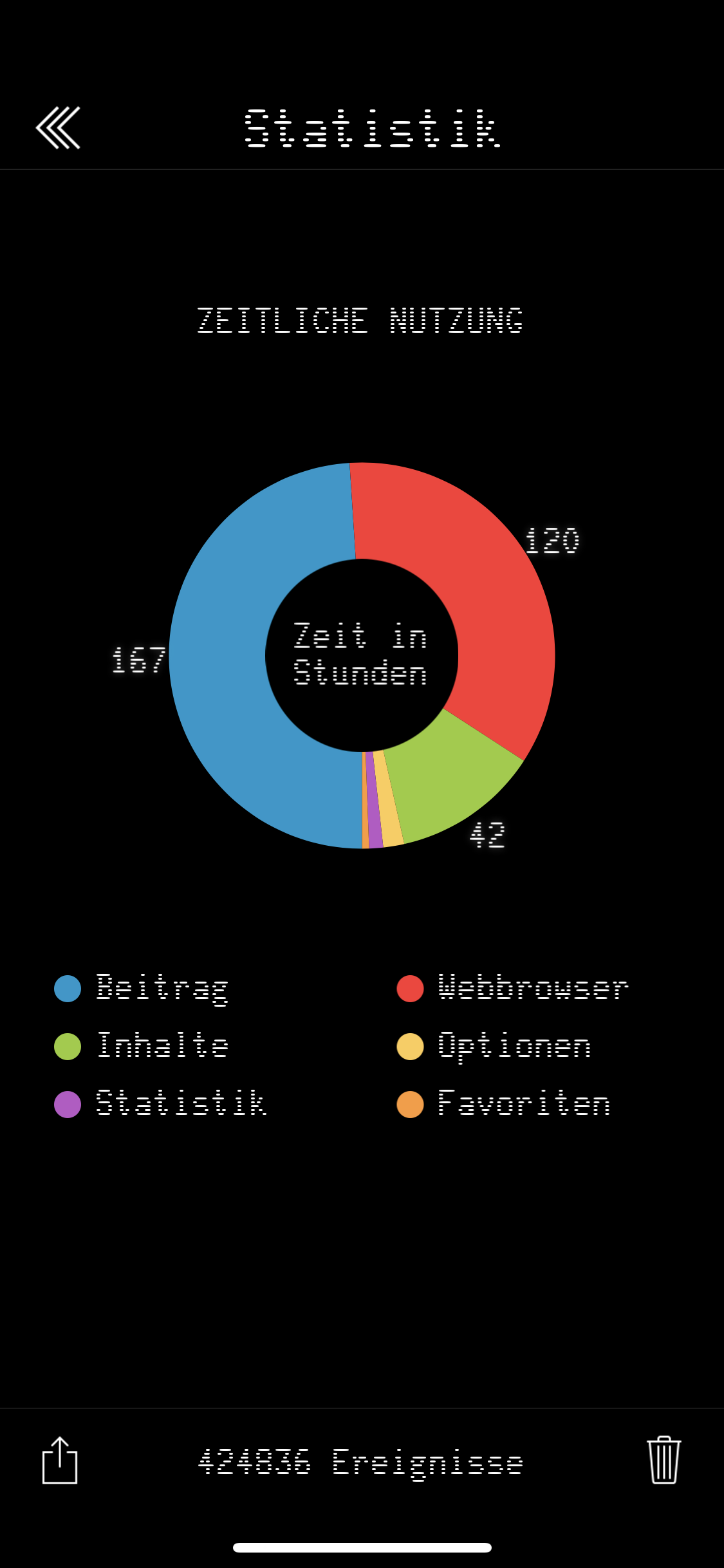
Ein weiteres schönes Feature, was gar nicht so trivial zu implementieren war, war die Statistik. Die App hat auf Wunsch eine Statistik über Verweilzeiten und Abrufzahlen geführt und ausschließlich lokal gespeichert (da wurde auch nie irgendwas aus der App jemals „nach Hause telefoniert“). Diese Statistik wurde dann fein in einem Tortendiagramm animiert aufbereitet. Es kann zuweilen erschrecken wenn einem die Statistik belegt, wieviel Lebenszeit man der App gewidmet hat. Ich werde meine persönliche Nutzungsstatistik weiter unten in meinem Fazit veröffentlichen.
Das Ende der App (2019)
Das Jahresende 2019 sollte dann das finale Ende der App einläuten (zumindest für alle anderen außer mir). Mitbekommen sollte ich das nur indirekt… über einen Post in Fefe’s Blog (den ich hier mal zitiere):
Einige Leser haben mich darauf hingewiesen, dass irgendeine ominöse App-Klitsche gegen Geld auf Android und Apple eine Fefe-App anbietet.
Nein, die App kommt nicht von mir. Nein, die haben vorher nicht gefragt. Nein, ich finde das nicht gut.
Sollte ich dagegen vorgehen? Gute Frage. Muss ich mal drüber nachdenken.
Der Beißreflex ist natürlich da. Auf der anderen Seite verkaufen die kein Abo, und natürlich hat die App nichts, was man nicht auch im Browser hat.
Ich sähe ehrlich gesagt akuteren Handlungsbedarf, wenn jemand eine App mit meinen Inhalten anbietet, die dann Werbung einblendet.
Auf der anderen Seite besteht natürlich die Gefahr, dass ich Nachahmer einlade, wenn ich da jetzt nicht verbrannte Erde hinterlasse.
Alles nicht so einfach. […]
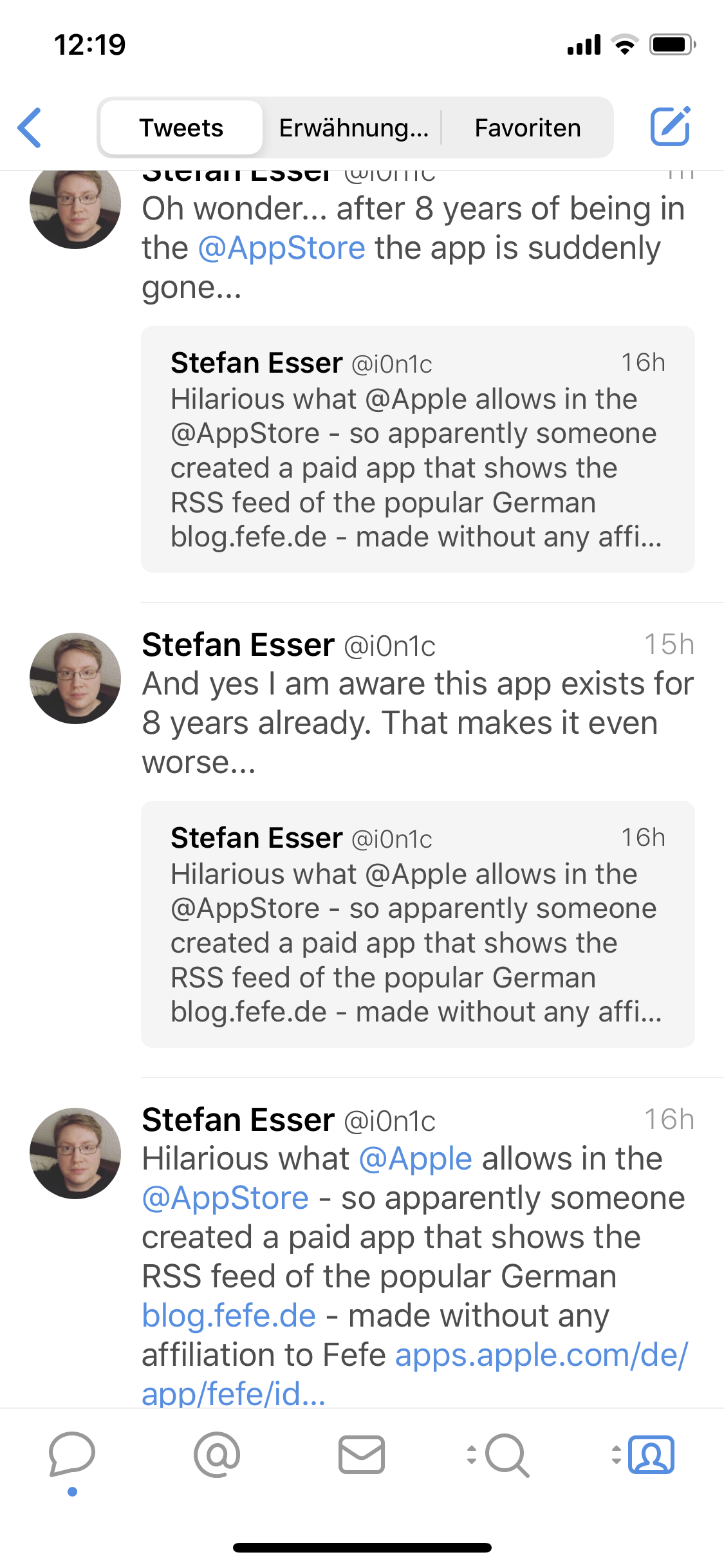
Ein wenig Recherche ergab dann auch, warum es da plötzlich eine solche Interruption gab, denn auf Twitter wurde ich recht schnell fündig:
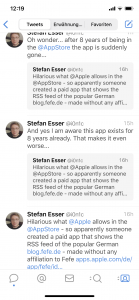
Ich möchte auf den Post den Fefe dazu schrieb gar nicht mehr groß eingehen (man soll Vergangenes ruhen lassen), aber es ist schlicht nicht wahr, dass Fefe nicht von der App wusste. Denn ich hatte ihm sogar am 2. Januar 2015 im Nachgang des Congress einen echten Brief (so richtig auf Papier) geschrieben an die Adresse die im Impressum steht:
Fefes Blog
c/o Raumfahrtagentur
Gerichtsstrasse 66
D-13347 Berlin
Hier ein Auszug aus dem Brief der an Fefe ging…

Wer sich fragt um welche Sticker es da in dem Brief geht… hier eine Übersicht:
Diese Sticker hatte ich für den Congress in 2014 erstellt und in den Stickerboxen des Congress auch unter die Teilnehmer gebracht. Ich fand das Logo so hübsch, dass ich da paar Sticker von haben wollte.
Persönliches Fazit
Es war von Beginn an ein Fehler mit einer App Fefe’s Blog noch bekannter zu machen und den Zugang dazu auf einem iOS Gerät komfortabel über eine App kostenlos zu ermöglichen. Denn die Inhalte sind meiner Ansicht nach polarisierend, vereinfachend und überwiegend negativer Natur. Sie propagieren eine negative Weltsicht und füttern die empörungssüchtigen Egos der Besucher mittels Zynismus und Schadenfreude. Das lenkt ab von den eigentlich konstruktiven Möglichkeiten sich in der Welt positiv einzubringen. Daher rate ich vom Lesen von Fefe denjenigen ab, die nicht ihre negative Weltsicht (die ihnen ihr Verstand in Form des eigenen Ego präsentiert) weiter verstärken möchten.
Die App war übrigens fast immer kostenlos, bis auf eine Ausnahme, bei der ich Spam-Kommentare durch einen Minimalpreis von 0,79€ eine Zeit lang ausschließen wollte. Aber auch das hab ich dann später gelassen. Auch ein In-App-Purchase gab es mal, aber das war mehr, um IAP auszuprobieren und wurde ebenfalls eingestellt. Leider listet der AppStore einmal angelegte IAP’s für immer und ewig. Mein Pech.
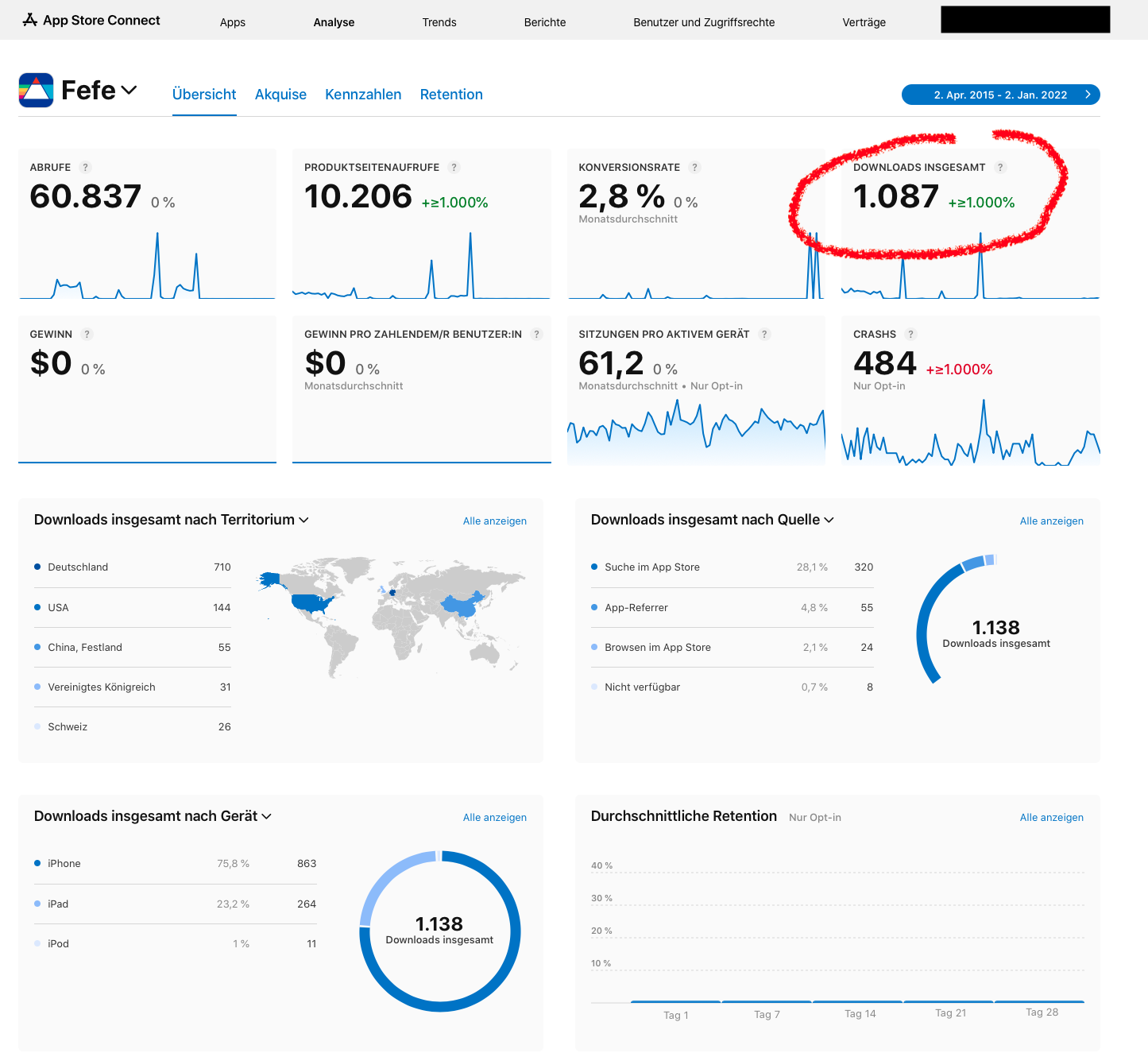
Wer denkt ich hätte damit Geld verdient… der mache sich bitte sein eigenes Bild aus den Umsatz/Gewinn-Zahlen die Apple hier für den Zeitraum 2015 bis heute anzeigt:
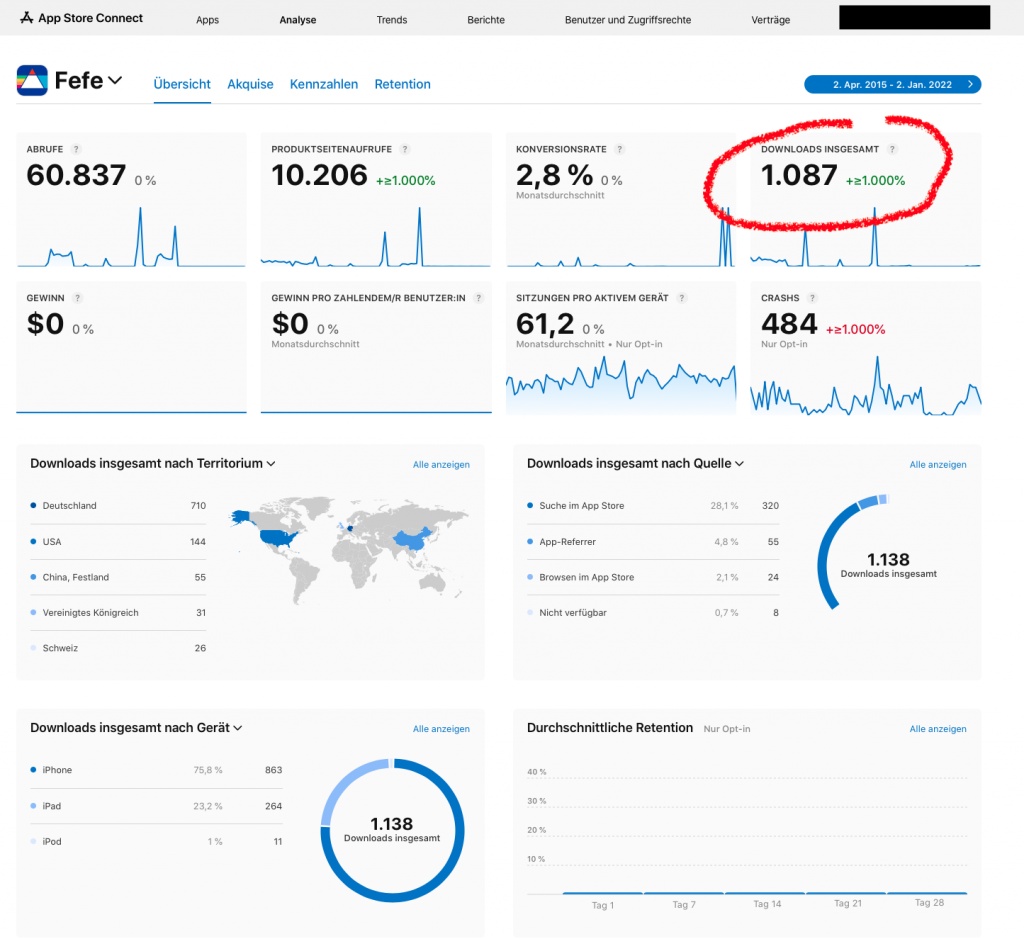
Muss enttäuschend sein, wenn man erkennen muss, dass lediglich ca. 1000 Downloads von der App existierten und damit genau 0$ Umsatz/Gewinn gemacht wurden, tja. Was mich eher ärgert, dass die Apps soviele Crashes hatte, LOL.
Ich finde es schade, auf welche Art und Weise die App aus dem Store letztlich verschwand und möchte hier nochmal klarstellen, dass ich die App selbst aus dem Store genommen habe, weil ich keinen Bock auf irgend einen Fefe-Mob hatte, der mir dann eventuell meine anderen (für mich wirklich wichtigen) Apps oder andere Infrastruktur kaputtmacht. Ich hoffe dass der Mensch auf Twitter (den ich im Screenshot da oben verlinkt habe) sich nach seiner Aktion besser gefühlt hat. Er hat sein Ego sicher prima mit neuem Futter versorgt. Schade, denn für alle anderen hat er ein weitgehend ehrenamtlich gepflegtes Stück Software ungeplant deorbit’ed, für 15 minutes of fame!
Ich bin ihm jedoch im nachhinein dankbar für diesen Vorgang und vergebe seinem Ego. Denn für mich persönlich hat der Vorgang einen neuen Weg aufgezeigt, der mir persönlich eine deutlich konstruktivere und positivere Weiterentwicklung ermöglicht, die mir wichtiger ist als eine App die ich als Just-for-Fun-Projekt hatte.
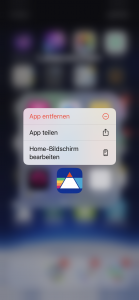
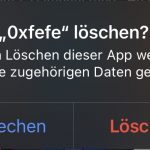
Noch wichtiger ist jedoch, dass ich auch Zeit gewinne. Die App hat mich nicht nur bei der Entwicklung wertvolle Lebenszeit gekostet, sondern insgesamt über 329 Stunden wertvolle Zeit, das sind fast 2 volle Wochen meiner Lebenszeit nur durch das Lesen der Inhalte. Hier ein letzter Blick auf die App, bevor ich sie auch von meinem iDevice für immer heute gelöscht habe:
| Letzte Übersicht |
Prozentuale Nutzung |
Absolute Zeit der Nutzung |
Anzahl Favoriten |
Löschung der App |
 |
 |
 |
 |
 |
Ich seh‘ es positiv: Ich hatte fast 10 Jahre meinen Spaß.
 Dennoch, ich sage explizit an dieser Stelle „Danke für Nichts!“, denn letztlich hat mich das Blog und seine Postings fehlgeleitet und mich wertvolle Lebenszeit gekostet. Zumindest bin ich u.a. durch diese App ein deutlich besserer App Developer geworden. Und diese App war unter anderem auch die Source Code Grundlage für mehrere Congress Fahrplan Apps die es sonst so vermutlich nie gegeben hätte:
Dennoch, ich sage explizit an dieser Stelle „Danke für Nichts!“, denn letztlich hat mich das Blog und seine Postings fehlgeleitet und mich wertvolle Lebenszeit gekostet. Zumindest bin ich u.a. durch diese App ein deutlich besserer App Developer geworden. Und diese App war unter anderem auch die Source Code Grundlage für mehrere Congress Fahrplan Apps die es sonst so vermutlich nie gegeben hätte:
 Why do I blog this? Ich schließe jetzt Anfang 2022 u.a. mit einigen Kapiteln meines bisherigen Lebens ab. Nämlich u.a. mit Negativität in jeder Form die meine Aufmerksamkeit in der Vergangenheit bekam. Fefe’s Blog ist für mich persönlich eine Quelle an Negativität. Mein Blick war lange Zeit verstellt das zu erkennen, aber es ist nicht gesund, sich Zynismus und Schadenfreude hinzugeben, oder auch nur seine negativen Erwartungen an die Zukunft verstärken zu lassen die so niemals eintreten müssen. Die Posts in Fefe’s Blog sollen aber Empörungscharakter haben und die negative Weltsicht von Fefe selbst bestärken, um letztlich sein Ego mit einem „Told you so“ zu boosten. Das Blog ist aus meiner Sicht ein Ego-Boosting-Projekt das jeden Besucher erfolgreich trollt. Eine positive Zukunft ist denkbar und möglich und es macht mehr Sinn sein eignes Ego nicht mit Negativität zu füttern und das fremde Ego von Fefe ebenso nicht mit Klickzahlen zu füttern. Man sollte es lassen die ganzen negativen Nachrichten in sich aufzusaugen. Das führt langfristig zu keiner einzigen Verbesserung. TL;DR: „Keep calm… …and don’t read Fefe.“ Andere bewerten das noch deutlich klarer und schrieben das auch nieder.
Why do I blog this? Ich schließe jetzt Anfang 2022 u.a. mit einigen Kapiteln meines bisherigen Lebens ab. Nämlich u.a. mit Negativität in jeder Form die meine Aufmerksamkeit in der Vergangenheit bekam. Fefe’s Blog ist für mich persönlich eine Quelle an Negativität. Mein Blick war lange Zeit verstellt das zu erkennen, aber es ist nicht gesund, sich Zynismus und Schadenfreude hinzugeben, oder auch nur seine negativen Erwartungen an die Zukunft verstärken zu lassen die so niemals eintreten müssen. Die Posts in Fefe’s Blog sollen aber Empörungscharakter haben und die negative Weltsicht von Fefe selbst bestärken, um letztlich sein Ego mit einem „Told you so“ zu boosten. Das Blog ist aus meiner Sicht ein Ego-Boosting-Projekt das jeden Besucher erfolgreich trollt. Eine positive Zukunft ist denkbar und möglich und es macht mehr Sinn sein eignes Ego nicht mit Negativität zu füttern und das fremde Ego von Fefe ebenso nicht mit Klickzahlen zu füttern. Man sollte es lassen die ganzen negativen Nachrichten in sich aufzusaugen. Das führt langfristig zu keiner einzigen Verbesserung. TL;DR: „Keep calm… …and don’t read Fefe.“ Andere bewerten das noch deutlich klarer und schrieben das auch nieder.

















{kind=link}
{kind=link}
{kind=link}